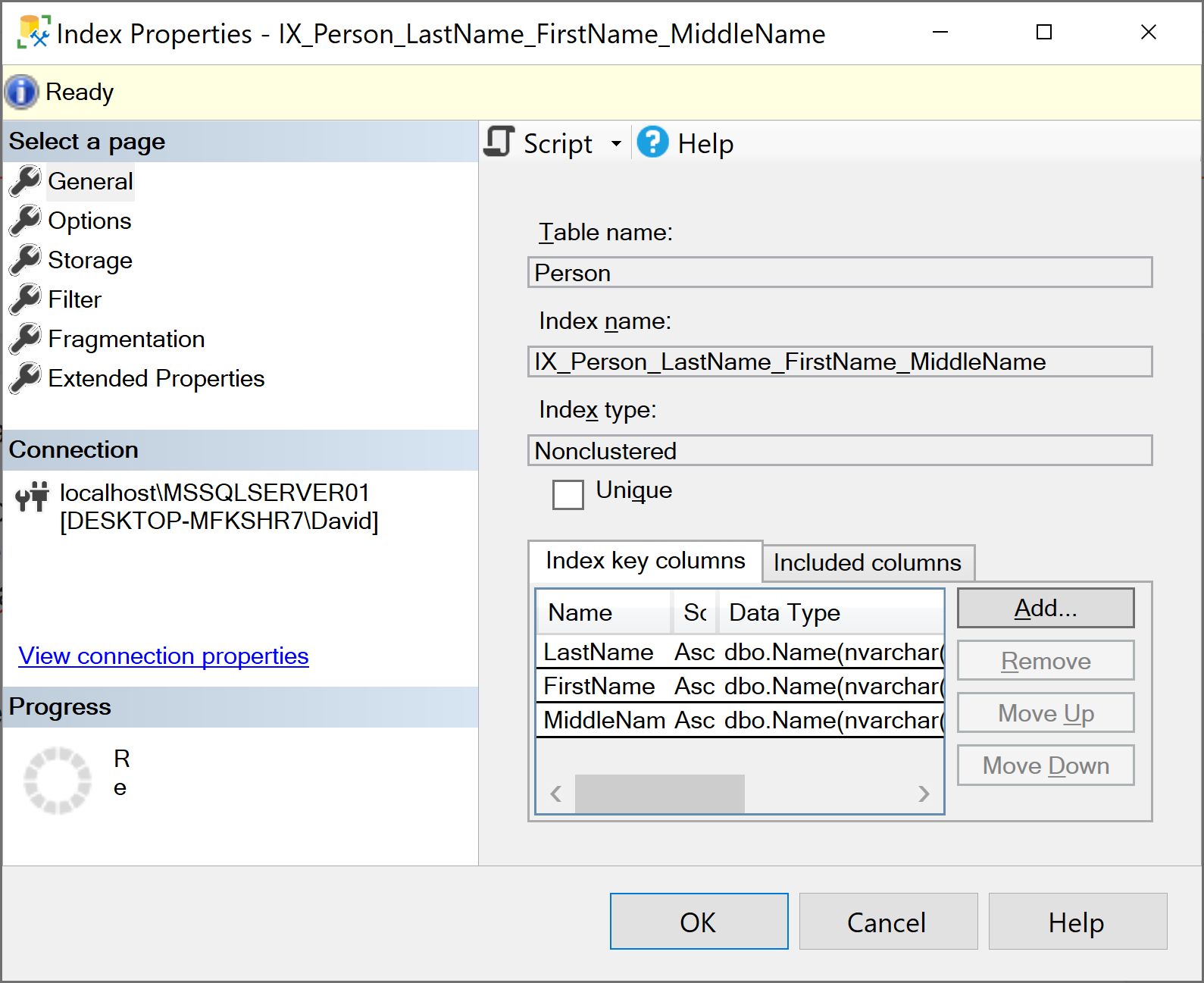
In this post I'm going to demonstrate one of the important factors of index design, the index column order. I'm going to be using the AdventureWorks2019 sample database and we'll take a look at the IX_Person_LastName_FirstName_MiddleName non-clustered index which is on the Person.Person table.
By looking at the index properties in Management Studio I can see the columns that make up the index and they have been put in the column order of LastName, FirstName and MiddleName. It's also worth noting the name of the index matches perfectly with the columns and their order which is a great example of a great naming convention!
So how does the column order affect our queries? Let's start with the following query:SELECT FirstName, LastName FROM Person.Person
Here we're selecting the FirstName and LastName columns from the Person.Person table where the LastName is 'Stewart', which is commonly referred to as filtering the rows. If I run the query it returns 93 rows and if I look at the execution plan (or query plan as it is also known) I can see that the optimiser has used an index seek operator on the IX_Person_LastName_FirstName_MiddleName index:

SELECT FirstName, LastName FROM Person.Person
WHERE FirstName = 'David';
Although FirstName is present in our index as the second column our query plan is a little bit different this time:


In Plan Explorer I can see that the engine has had to read through 19972 rows to return 87 however our first query that utilised the index seek operator has only had to read through 93 rows (and returned the same number):

Its also worth noting that for our index scan query we also see a Reason for Early Termination: Good Enough Plan Found which means the optimiser has retrieved the execution plan from cache, we don't see this message for the plan using an index seek as the optimiser has used a Trivial Plan instead.
This shows how a column cannot be effectively used for filtering (using the where clause in our query) unless it is the first column in an index. In the second query the index has still been used by the optimiser but it is unable to perform a more efficient seek operation and instead has had to scan (or read) through the entire index to return our results.
Now we could create an additional non-clustered index that has the FirstName column as the first column but we also have to determine the suitability of that index. If we were to create indexes for every single query on our database we'd end up with a lot of surplus indexes that are barley used which will inevitably cause a lot of overhead for things like table update operations and index maintenance.
It's much more likely for queries to be filtering on LastName so that's a perfect candidate for a non-clustered index, if we're never going to use the FirstName column in where clauses, joins etc then an index using that column isn't goign to provide any benefit which is why understanding how the columns will be used in our queries is the most important factor in designing index strategies.





